Java8学习(4)-Stream流
Stream和Collection的区别是什么
流和集合的区别是什么?
粗略地说, 集合和流之间的差异就在于什么时候进行计算。集合是一个内存中的数据结构,它包含数据结构中目前所有的值–集合中的每个元素都得先计算出来才能添加到内存里。(你可以往集合里加东西或者删东西,但是不管什么时候,集合中的每个元素都是放在内存里的,元素都得计算出来才能成为集合的一部分。)
相比之下,流则是在概念上固定的数据结构(你不能添加或者删除元素),其元素则是按需计算的。这对编程有很大的好处。用户仅仅从流中提取需要的值,而这些值–在用户看不见的地方–只会按需生成。这是一种生产者 - 消费者的关系。从另一个角度来说,流就像一个延迟创建的集合:只有在消费者要求的时候才会计算值。
Stream是内部迭代
一个明显的区别是迭代方式不同。Collection需要手动for-each或者使用Iterator在外部迭代。而Stream则开启后可以直接对单个元素进行操作,内部帮你做好了迭代工作。
内部迭代的好处是可一个更好的并行。自己手写迭代需要处理好每次迭代的内容。为了提高执行效率,也许会把多个处理逻辑写到同一个遍历里。比如,有同事看到从scala转过来的同事的代码,说他写的代码经常重复好多次。scala是函数式语言,和流天然集成。而我们惯性的做法,还是把一堆操作逻辑写到同一个循环体中,来满足自己对所谓的性能要求的洁癖。这常常会使得可读性变差。很厌烦阅读超过100行的代码,尤其代码还有首尾同步处理的逻辑(for, try-catch),很容易出错。多写一次循环来做这些事情,心理又过不去。
Stream开启流之后,系统内部会分析对元素的操作是否可以并行,然后合并执行。也就是说,看起来,自己filter-map-filter-map-group很多次,但真实执行的时候并不是遍历了很多次。至于到底遍历了多少次。这是一个好问题,后面会说明这个问题。
使用流Stream的注意事项
流只能消费一次。比如,foreach只能遍历一次stream。再次则会抛异常。
流操作
针对流的操作方式两种:
中间操作
可以连接起来的流操作叫做中间操作。诸如filter或map等中间操作会返回另一个流。这让多个操作可以连接起来形成一个查询。但是,除非调用一个终端操作,比如collect,foreach, 否则中间操作不会执行—-它们很懒。这是因为中间操作一般可以合并起来,在终端操作时一次性全部处理。
终端操作
关闭流的操作叫做终端操作。终端操作会从流的流水线生成结果。
使用流
本文demo源码: https://github.com/Ryan-Miao/someTest/tree/master/src/main/java/com/test/java8/streams
新建一个Entity作为基本元素。
1 | package com.test.java8.streams.entity; |
最常用,最简单的用法
Stream API支持许多操作,这些操作能让你快速完成复杂的数据查询,比如筛选、切片、映射、查找、匹配和归约。
1 | package com.test.java8.streams; |
stream()将一个集合转换成一个流,流和list一样,都是单元素的集合体。filter()接受一个布尔值lambda,即一个谓词。当表达式的value是true的时候,该元素通过筛选。map()接受一个转换lambda,将一个元素class映射成另一个class。collect收集器,汇总结果,触发流,终端操作。
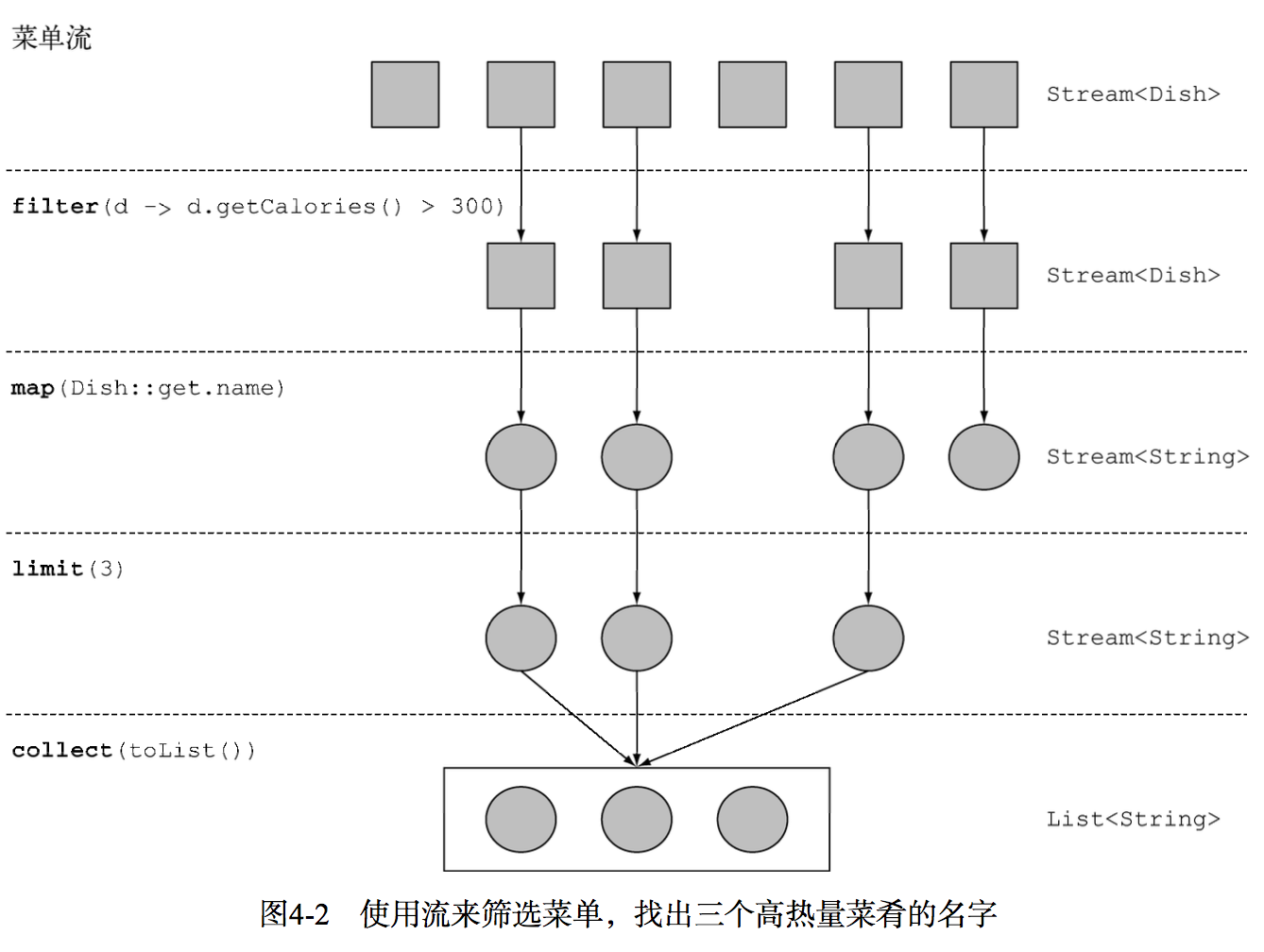
谓词筛选filter
谓词是一个返回boolean的函数,也就是条件,通过这个条件进行筛选。
1 |
|
这里,filter的参数就是一个谓词,配合filter,可以筛选结果,只有返回值是true的item会通过。
去重复distinct
distinct()
截短流limit
limit(n)
跳过元素skip
skip(n)。 通过limit(n)形成互补关系。
映射map
map, stream的核心操作。接收一个参数,用来把一个对象转换为另一个。demo同上。下面看具体需求。
1 | /** |
接收一个Function函数,然后返回Stream. 而Function在前面已经介绍过了。我们看核心的方法。
1 |
|
Function函数的功能就是把参数转换成另一个类型的对象,返回。也就是a -> {return b;}。
瞥一眼Peek
上面map的需求特别多,但有时候我并不想返回另一个对象,我只是想要把原来的对象加工一个下,还是返回原来的对象。用map也是可以的,只要返回同一个对象就行。但IDEA会推荐用peek()。
比如,我想把list的user全部取出来,把updateDate更新为当前时间。
1 |
|
源码里是这样写的
1 | /** |
而Consumer同样也在之前出现过
1 |
|
也就是说,peek()的本意是将对象取出来,消一遍,并不是像我的说的那样返回原对象,因为参数并不是Function, 而是Consumer。我之所以这么说是因为Function也可以做到这个功能,只要将返回值变为当前对象即可。而peek里,我们可以修改当前对象的属性,也是会生效的。
流的扁平化faltMap
我们前面讲的函数都是处理一个序列,一个list,一个Stream里的数据。如果一个Stream的元素也是另一个stream呢?我还想把这个Stream的元素的stream打散,最终输出一个stream。比如下面这个例子。统计单词列表中出现的字母。
1 | final List<String> words = Lists.newArrayList( "Hello", "worlds"); |
打印的结果为:
H,e,l,l,o,
w,o,r,l,d,s,
显然,目标没达到。map之后的stream已经变成Stream<Stream<String>>。应该如何把里面的Stream打开,最后拼接起来呢。最直观的想法就是用一个新的list,将我们刚才foreach打印的步骤中的操作变成插入list。但这显然不是函数式编程。
flatMap可以接收一个参数,返回一个流,这个流可以拼接到最外层的流。说的太啰嗦,看具体用法。
1 |
|
- 第一步,用map将一个String对象映射成String[]数组。
- 第二步,将这个返回的对象映射成Stream,这里的数组转Stream即
Arrays::stream. - 第三步,用flatMap
以上可以合并为一步: .flatMap(w -> Arrays.stream(w.split("")))
最终打印结果:
[H, e, l, o, w, r, d, s]
查找和匹配
另一个常见的数据处理套路是看看数据集中的某些元素是否匹配一个给定的属性。Stream API通过allMatch, anyMatch,noneMatch,findFirst,findAny方法提供了这样的工具。
比如,找到任何一个匹配条件的。
1 |
|
101
12
有偶数
上述只是确定下是不是存在,在很多情况下这就够了。至于FindAny和FindFirst则是找到后返回,目前还没遇到使用场景。
归约Reduce
Google搜索提出的Map Reduce模型,Hadoop提供了经典的开源实现。在Java中,我们也可以手动实现这个。

reduce的操作在函数式编程中很常见,作用是将一个历史值与当前值做处理。比如求和,求最大值。
求和的时候,我们会将每个元素累加给sum。用reduce即可实现:
1 |
|
打印结果为:
1 | 1 2 |
给一个初始值
1 | int rs = IntStream.rangeClosed(1, 100) |
同样,可以用来求最大值。
1 | List<Integer> nums = Lists.newArrayList(3, 1, 4, 0, 8, 5); |
这里的比较函数恰好是Integer的一个方法,为增强可读性,可以替换为:
1 | nums.stream().reduce(Integer::max).ifPresent(System.out::println); |
接下来,回归我们最初的目标,实现伟大的Map-Reduce模型。比如,想要知道有多少个菜(一个dish list)。
1 |
|
归约的优势和并行化
相比于用foreach逐步迭代求和,使用reduce的好处在于,这里的迭代被内部迭代抽象掉了,这让内部实现得以选择并行执行reduce操作。而迭代式求和例子要更新共享变量sum,这不是那么容易并行化的。如果你加入了同步,很可能会发现线程竞争抵消了并行本应带来的性能提升!这种计算的并行化需要另一种方法:将输入分块,分块求和,最后再合并起来。但这样的话代码看起来就完全不一样了。后面会用分支/合并框架来做这件事。但现在重要的是要认识到,可变的累加模式对于并行化来说是死路一条。你需要一种新的模式,这正是reduce所提供的。传递给reduce的lambda不能更改状态(如实例变量),而且操作必须满足结合律才可以按任意顺序执行。
流操作的状态:无状态和有状态
你已经看到了很多的流操作,乍一看流操作简直是灵丹妙药,而且只要在从集合生成流的时候把Stream换成parallelStream就可以实现并行。但这些操作的特性并不相同。他们需要操作的内部状态还是有些问题的。
诸如map和filter等操作会从输入流中获取每一个元素,并在输出流中得到0或1个结果。这些操作一般是无状态的:他们没有内部状态(假设用户提供的lambda或者方法引用没有内部可变状态)。
但诸如reduce、sum、max等操作需要内部状态来累积结果。在前面的情况下,内部状态很小。在我们的例子里就是一个int或者double。不管流中有多少元素要处理,内部状态都是有界的。
相反,诸如sort或distinct等操作一开始都和filter和map差不多–都是接受一个流,再生成一个流(中间操作), 但有一个关键的区别。从流中排序和删除重复项都需要知道先前的历史。例如,排序要求所有元素都放入缓冲区后才能给输出流加入一个项目,这一操作的存储要求是无界的。要是流比较大或是无限的,就可能会有问题(把质数流倒序会做什么呢?它应当返回最大的质数,但数学告诉我们他不存在)。我们把这些操作叫做有状态操作。
注
以上内容均来自《Java8 In Action》。





